Mysql集群
MySQL支持的复制方式
- 基于语句的复制(也称为逻辑复制)主要是指,在主数据库上执行的SQL语句,在从数据库上会重复执行一遍 。MySQL默认采用的就是这种复制,效率比较高。但是也是有一定的问题的,如果SQL中使用uuid()、rand()等函数,那么复制到从库的数据就会有偏差。
- 基于行的复制,指将更新处理后的数据复制到从数据库,而不是执行一边语句 。从MySQL5.1的版本才被支持。
- 混合复制,默认采用语句复制,当发现语句不能进行精准复制数据时(例如语句中含有uuid()、rand()等函数),采用基于行的复制 。
主从复制原理
MySQL的复制原理概述上来讲大体可以分为这三步
- 在主库上把数据更改,记录到二进制日志(Binary Log)中。
- 从库将主库上的日志复制到自己的中继日志(Relay Log)中。
- 备库读取中继日志中的事件,将其重放到备库数据之上。
MySQL主从复制模式
MySQL的主从复制其实是支持, 异步复制 、 半同步复制 、 GTID复制 等多种复制模式的。
异步模式
MySQL的默认复制模式就是异步模式,主要是 指MySQL的主服务器上的I/O线程,将数据写到binlong中就直接返回给客户端数据更新成功,不考虑数据是否传输到从服务器,以及是否写入到relaylog中 。在这种模式下,复制数据其实是有风险的,一旦数据只写到了主库的binlog中还没来得及同步到从库时,就会造成数据的丢失。
但是这种模式确也是效率最高的,因为变更数据的功能都只是在主库中完成就可以了,从库复制数据不会影响到主库的写数据操作。
半同步模式
MySQL从 5.5 版本开始通过以插件的形式开始支持半同步的主从复制模式。什么是半同步主从复制模式呢?
这里通过对比的方式来说明一下:
- 异步复制模式 :上面我们已经介绍了,异步复制模式,主库在执行完客户端提交的事务后,只要将执行逻辑写入到binlog后,就立即返回给客户端,并不关心从库是否执行成功,这样就会有一个隐患,就是在主库执行的binlog还没同步到从库时,主库挂了,这个时候从库就就会被强行提升为主库,这个时候就有可能造成数据丢失。
- 同步复制模式 :当主库执行完客户端提交的事务后,需要等到所有从库也都执行完这一事务后,才返回给客户端执行成功。因为要等到所有从库都执行完,执行过程中会被阻塞,等待返回结果,所以性能上会有很严重的影响。
- 半同步复制模式 :半同步复制模式,可以说是介于异步和同步之间的一种复制模式,主库在执行完客户端提交的事务后,要等待至少一个从库接收到binlog并将数据写入到relay log中才返回给客户端成功结果。半同步复制模式,比异步模式提高了数据的可用性,但是也产生了一定的性能延迟,最少要一个TCP/IP连接的往返时间。
半同步复制模式,可以很明确的知道,在一个事务提交成功之后,此事务至少会存在于两个地方一个是主库一个是从库中的某一个。 主要原理是,在master的dump线程去通知从库时,增加了一个ACK机制,也就是会确认从库是否收到事务的标志码,master的dump线程不但要发送binlog到从库,还有负责接收slave的ACK。当出现异常时,Slave没有ACK事务,那么将自动降级为异步复制,直到异常修复后再自动变为半同步复制
半同步复制的隐患
半同步复制模式也存在一定的数据风险,当事务在主库提交完后等待从库ACK的过程中,如果Master宕机了,这个时候就会有两种情况的问题。
- 事务还没发送到Slave上 :若事务还没发送Slave上,客户端在收到失败结果后,会重新提交事务,因为重新提交的事务是在新的Master上执行的,所以会执行成功,后面若是之前的Master恢复后,会以Slave的身份加入到集群中,这个时候,之前的事务就会被执行两次,第一次是之前此台机器作为Master的时候执行的,第二次是做为Slave后从主库中同步过来的。
- 事务已经同步到Slave上 :因为事务已经同步到Slave了,所以当客户端收到失败结果后,再次提交事务,你那么此事务就会在当前Slave机器上执行两次。
为了解决上面的隐患,MySQL从5.7版本开始,增加了一种新的半同步方式。新的半同步方式的执行过程是将“ Storage Commit ”这一步移动到了“ Write Slave dump ”后面。这样保证了 只有Slave的事务ACK后,才提交主库事务 。MySQL 5.7.2版本新增了一个参数来进行配置: rpl_semi_sync_master_wait_point ,此参数有两个值可配置:
GTID模式
// TODO
Mysql集群常用高可用方案
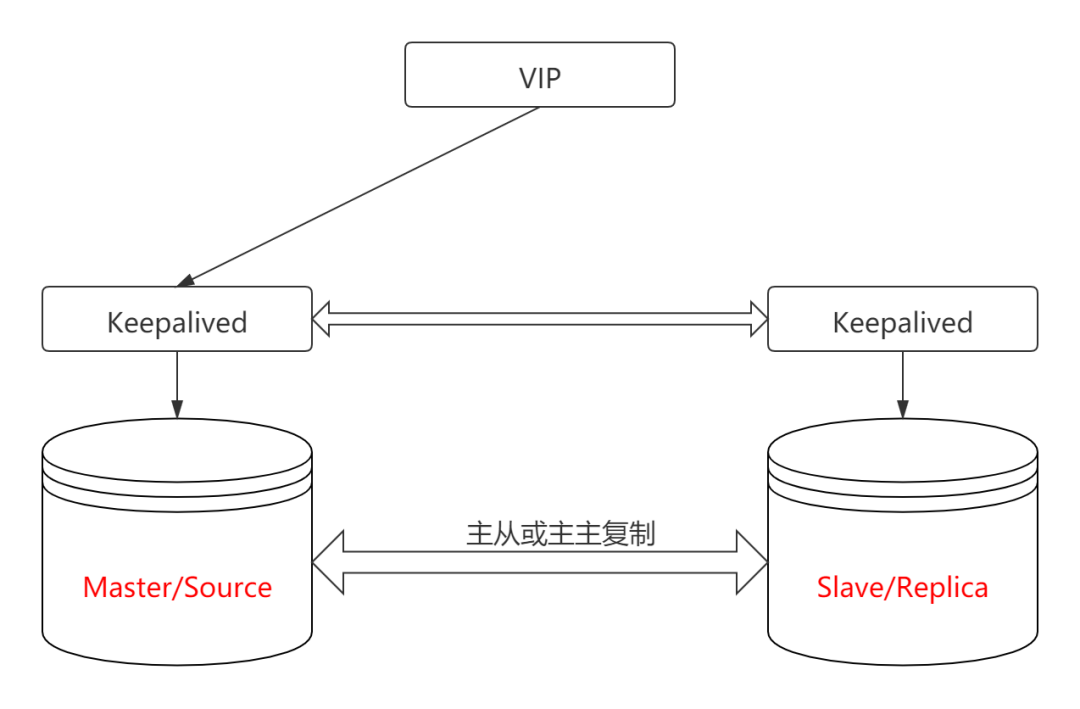
1、主从或主主 + Keepalived
主从或主主 + Keepalived 算是历史比较悠久的 MySQL 高可用方案,常见架构如下:
2、MySQL Cluster
mysql集群(MySQL Cluster)也是mysql官方提供的。
MySQL Cluster是多主多从结构的
就各个集群方案来说,其优势为:
mysql官方提供的工具,无需第三方插件。
高可用性优秀,99.999%的可用性,可以自动切分数据,能跨节点冗余数据(其数据集并不是存储某个特定的MySQL实例上,而是被分布在多个Data Nodes中,即一个table的数据可能被分散在多个物理节点上,任何数据都会在多个Data Nodes上冗余备份。任何一个数据变更操作,都将在一组Data Nodes上同步,以保证数据的一致性)。
可伸缩性优秀,能自动切分数据,方便数据库的水平拓展。
负载均衡优秀,可同时用于读操作、写操作都都密集的应用,也可以使用SQL和NOSQL接口访问数据。
多个主节点,没有单点故障的问题,节点故障恢复通常小于1秒。
其劣势为:
架构模式和原理很复杂。
只能使用存储引擎 NDB ,与平常使用的InnoDB 有很多明显的差距。比如在事务(其事务隔离级别只支持Read Committed,即一个事务在提交前,查询不到在事务内所做的修改),外键(虽然最新的NDB 存储引擎已经支持外键,但性能有问题,因为外键所关联的记录可能在别的分片节点),表限制上的不同,可能会导致日常开发出现意外。点击查看具体差距比较
作为分布式的数据库系统,各个节点之间存在大量的数据通讯,比如所有访问都是需要经过超过一个节点(至少有一个 SQL Node和一个 NDB Node)才能完成,因此对节点之间的内部互联网络带宽要求高。
Data Node数据会被尽量放在内存中,对内存要求大,而且重启的时候,数据节点将数据load到内存需要很长时间。
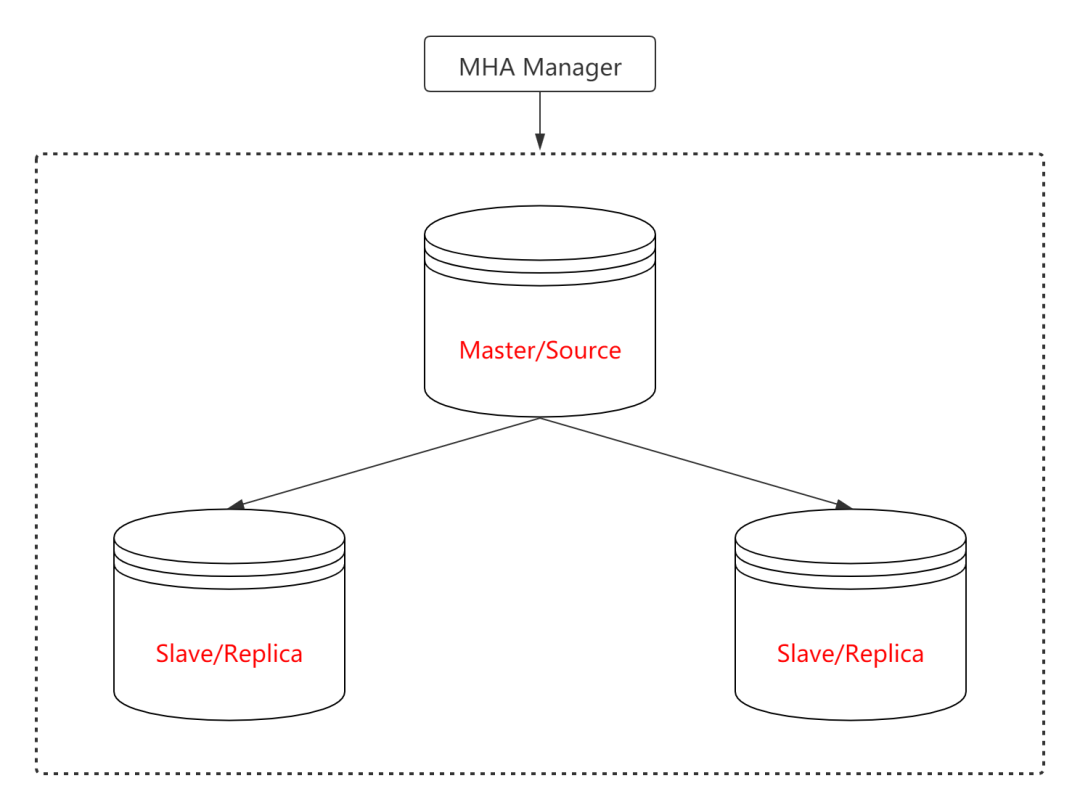
3、MHA(Master High Avaliable)
MHA(Master High Avaliable) 是一款 MySQL 开源高可用程序,MHA 在监测到主实例无响应后,可以自动将同步最靠前的 Slave 提升为 Master,然后将其他所有的 Slave 重新指向新的 Master。常见架构如下:
优点
- 可以根据需要扩展 MySQL 的节点数量。
- 只要复制没有延迟,MHA 通常可以在几秒内实现故障切换。
- 可以使用任何存储引擎。
缺点
- 仅监视主数据库。
- 需要做 SSH 互信
- 使用 Perl 开发,二次开发困难。
- 跟不上 MySQL 新版本,最近一次发版是 2018 年。
4、 Xenon
Xenon 是一个使用 Raft 协议的 MySQL 高可用和复制管理工具,使用 Go 语音编写。架构图如下:
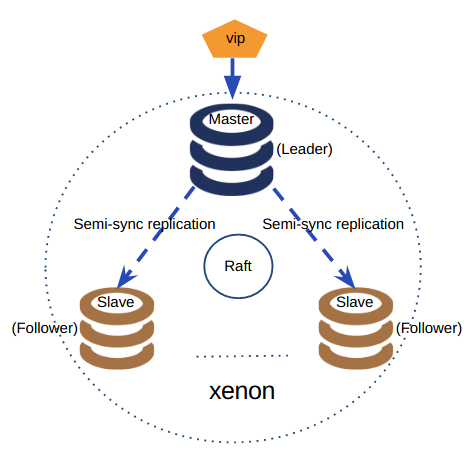
Xenon 基于 Raft 协议进行无中心化选主,并能实现秒级切换。
优点
- 不需要管理节点。
- 无数据丢失的快速故障转移。
缺点
- 只适用于 GTID。
- 默认情况下,Xenon 和 MySQL 跑在同一个账号下。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!