跳跃表
zset底层数据结构
当有序集合对象可以同时满足以下两个条件时,对象使用 ziplist 编码:
1.有序集合保存的元素数量小于128个;
2.有序集合保存的所有元素成员的长度都小于64字节;
不能满足以上两个条件的有序集合对象将使用 skiplist 编码。
ziplist
ziplist 是一个经过特殊编码的双向链表,它的设计目标是节约内存。它可以存储字符串或者整数。其中整数是按二进制进行编码的,而不是字符串序列。它能以 O(1) 的时间复杂度在列表的两端进行 push 和 pop 操作。但是由于每个操作都需要对 ziplist 所使用的内存进行重新分配,所以实际操作的复杂度与 ziplist 占用内存大小有关。

列表 zlbytes 属性的值为 0x50(十进制 80),表示压缩列表的总长为 80 字节。
列表 zltail 属性的值为 0x3c(十进制 60),这表示如果我们有一个指向压缩列表起始地址的指针 p,那么只要用指针 p 加上偏移量 60,就可以计算出表尾节点 entry3 的地址。
列表 zllen 属性的值为 0x3(十进制 3),表示压缩列表包含三个节点。

previous_entry_length 字段表示前一个元素的字节长度,占 1 个或者 5 个字节:
- 当前一个元素的长度小于 254 字节时,用 1 个字节表示;
- 当前一个元素的长度大于或等于 254 字节时,用 5 个字节来表示。而此时
previous_entry_length字段的第一个字节是固定的 0xFE(十进制为 254),后面 4 个字节才真正表示前一个元素的长度。 - 假设已知当前元素的首地址为 p,那么
p-previous_entry_length就是前一个元素的首地址,从而实现压缩列表从尾到头的遍历。
encoding 字段表示当前元素的编码,记录了节点的 content 字段所保存数据的类型以及长度:
- 1 字节、2 字节或者 5 字节长,值的最高位为 00、01 或者 10 的是字节数组编码:这种编码表示节点的 content 属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录;
- 1 字节长,值的最高位以 11 开头的是整数编码:这种编码表示节点的 content 字段保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录;
content 字段存储节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
skiplist
为了解决一个有序表查询的问题,发明的跳跃表,为了插入方便选择用链表,但是链表怎么解决查找的问题呢?这就引出我们要介绍的跳跃表
从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数
为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉
搜索树,我们把一些节点提取出来,作为索引。得到如下结构:
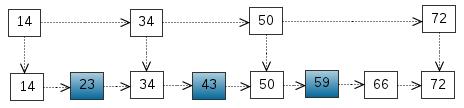
这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
可以再把部分一级索引的数字提取出来成为二级索引
跳跃表的插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)
然后在 Level 1 … Level K 各个层的链表都插入元素。
例子:插入 119, K = 2
丢硬币决定 K
插入元素的时候,元素所占有的层数完全是随机的,通过一下随机算法产生:
跳表的高度。
n 个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数 K,
跳表的高度等于这 n 次实验中产生的最大 K
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的
期望值是 2n。本质是以空间换时间
为啥 redis 使用跳表(skiplist)而不是使用 red-black?
1)在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
2)平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
3)从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
4、 在并发环境下skiplist有另外一个优势,红黑树在插入和删除的时候可能需要做一些rebalance的操作,这样的操作可能会涉及到整个树的其他部分,而skiplist的操作显然更加局部性一些,锁需要盯住的节点更少,因此在这样的情况下性能好一些。
5)从算法实现难度上来比较,skiplist比平衡树要简单得多。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!