多版本并发控制
数据库MVCC
MVCC(multiVersion Concurrency Control)多版本并发控制协议
在实际环境中数据库的事务大都是只读的,读请求是写请求的很多倍,如果写请求和读请求之前没有并发控制机制,那么最坏的情况也是读请求读到了已经写入的数据,这对很多应用完全是可以接受的。
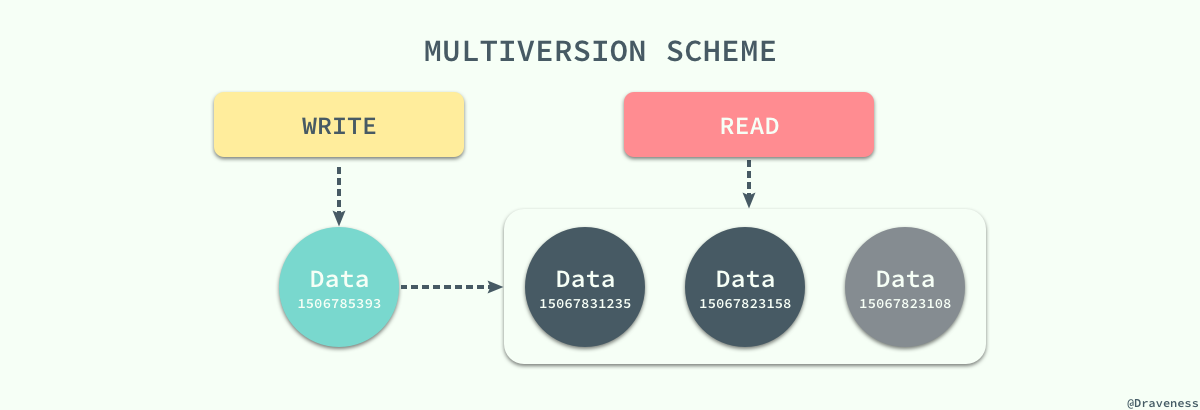
在这种大前提下,数据库系统引入了另一种并发控制机制 - 多版本并发控制(Multiversion Concurrency Control),每一个写操作都会创建一个新版本的数据,读操作会从有限多个版本的数据中挑选一个最合适的结果直接返回;在这时,读写操作之间的冲突就不再需要被关注,而管理和快速挑选数据的版本就成了 MVCC 需要解决的主要问题。
Mysql中MVCC
MySQL 中实现的多版本两阶段锁协议(Multiversion 2PL)将 MVCC 和 2PL 的优点结合了起来,每一个版本的数据行都具有一个唯一的时间戳,当有读事务请求时,数据库程序会直接从多个版本的数据项中具有最大时间戳的返回。
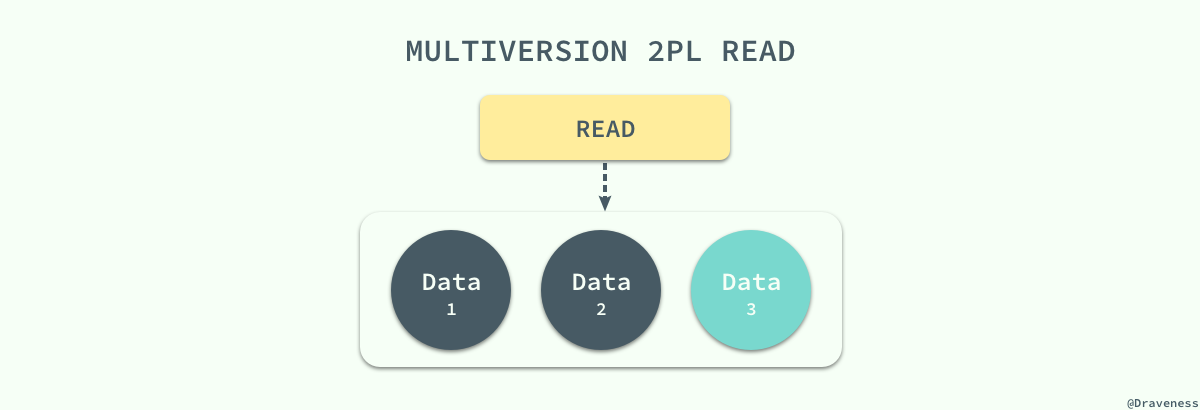
更新操作就稍微有些复杂了,事务会先读取最新版本的数据计算出数据更新后的结果,然后创建一个新版本的数据,新数据的时间戳是目前数据行的最大版本 +1:

数据版本的删除也是根据时间戳来选择的,MySQL 会将版本最低的数据定时从数据库中清除以保证不会出现大量的遗留内容。
PostgreSQL 与 MVCC
与 MySQL 中使用悲观并发控制不同,PostgreSQL 中都是使用乐观并发控制的,这也就导致了 MVCC 在于乐观锁结合时的实现上有一些不同,最终实现的叫做多版本时间戳排序协议(Multiversion Timestamp Ordering),在这个协议中,所有的事务在执行之前都会被分配一个唯一的时间戳,每一个数据项都有读写两个时间戳:

当 PostgreSQL 的事务发出了一个读请求,数据库直接将最新版本的数据返回,不会被任何操作阻塞,而写操作在执行时,事务的时间戳一定要大或者等于数据行的读时间戳,否则就会被回滚。
这种 MVCC 的实现保证了读事务永远都不会失败并且不需要等待锁的释放,对于读请求远远多于写请求的应用程序,乐观锁加 MVCC 对数据库的性能有着非常大的提升;虽然这种协议能够针对一些实际情况做出一些明显的性能提升,但是也会导致两个问题,一个是每一次读操作都会更新读时间戳造成两次的磁盘写入,第二是事务之间的冲突是通过回滚解决的,所以如果冲突的可能性非常高或者回滚代价巨大,数据库的读写性能还不如使用传统的锁等待方式。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!